
🏢6. API 设计
作者:Bryan Cooksey 发布日期:2014年4月22日
这一章标志着我们在API的探索中迈出的一个转折点。我们已经完成了基础知识的介绍,现在准备看到之前的概念如何结合起来形成一个API。在本章中,我们通过设计一个API来讨论其组成部分。
组织数据
《国家地理》估计,2011年美国人拍摄了800亿张照片。由于照片如此之多,可以想象人们在电脑上对它们进行组织的不同方法。有些人喜欢把所有照片都倒入一个文件夹中。而其他人则会将照片精心地按年份、月份和事件的层次结构进行分类。
当构建API时,公司也会对组织方式进行类似的思考。正如我们在第一章中提到的,API的目的是使计算机能够轻松处理公司的数据。考虑到易用性,一家公司可能决定为所有数据提供一个统一的URL,并使其可搜索(有点像为所有照片设定一个文件夹)。另一家公司可能决定为每个数据单独分配一个URL,并按层次结构进行组织(类似于为照片设置文件夹和子文件夹)。每家公司根据自身的特定情况选择最佳的API结构方式,遵循现有的行业最佳实践。
从架构风格开始
在讨论API时,你可能会听到关于"soap"和"rest"的讨论,不禁想知道软件开发人员是在做工作还是在计划度假。事实上,这些是基于Web的API最常见的两种架构的名称。SOAP(曾经是一个缩写)是一种基于XML的设计,具有标准化的请求和响应结构。REST代表表述性状态转移(Representational State Transfer),是一种更开放的方法,提供了许多约定,但许多决策留给API设计人员。
SOAP最初代表简单对象访问协议(Simple Object Access Protocol)。它最初用于一种非常特定类型的API访问。随着开发人员找到将其应用于更多情况的方法,该名称不再适用,因此在SOAP 1.2版本中放弃了这个缩写。
在本课程中,你可能已经注意到我们对REST API有一种偏好。这主要是因为REST的广泛采用率。这并不是说SOAP是不好的;它也有其优点。然而,我们的讨论重点将放在REST上,因为这可能是你遇到的API类型。在接下来的章节中,我们将详细介绍构成REST API的各个组成部分。
SOAP提供了一个非常结构化的架构。这种结构提供了系统的可靠性,标准扩展以添加协议功能,并使工具能够生成代码,节省开发时间。
我们的第一个资源
在第二章中,我们简要讨论了资源(resources)。回想一下,资源是API的名词(顾客和比萨)。这些是我们希望世界能够通过我们的API与之交互的东西。
为了了解公司如何设计API,让我们以比萨店为例进行尝试。我们首先添加订购比萨的功能。
为了让客户端能够与我们交流比萨,我们需要做以下几件事情:
确定需要提供哪些资源。
为这些资源分配URL。
决定客户端可以在这些资源上执行哪些操作。
确定每个操作所需的数据片段及其格式。
选择资源可能是一个困难的首要任务。解决这个问题的一种方法是逐步分析典型的交互过程。对于我们的比萨店,我们可能有一个菜单。菜单上有比萨。当顾客想让我们为他们制作其中一种比萨时,他们会下订单。在这种情况下,菜单、比萨、顾客和订单都是不错的资源候选项。我们先从订单开始。
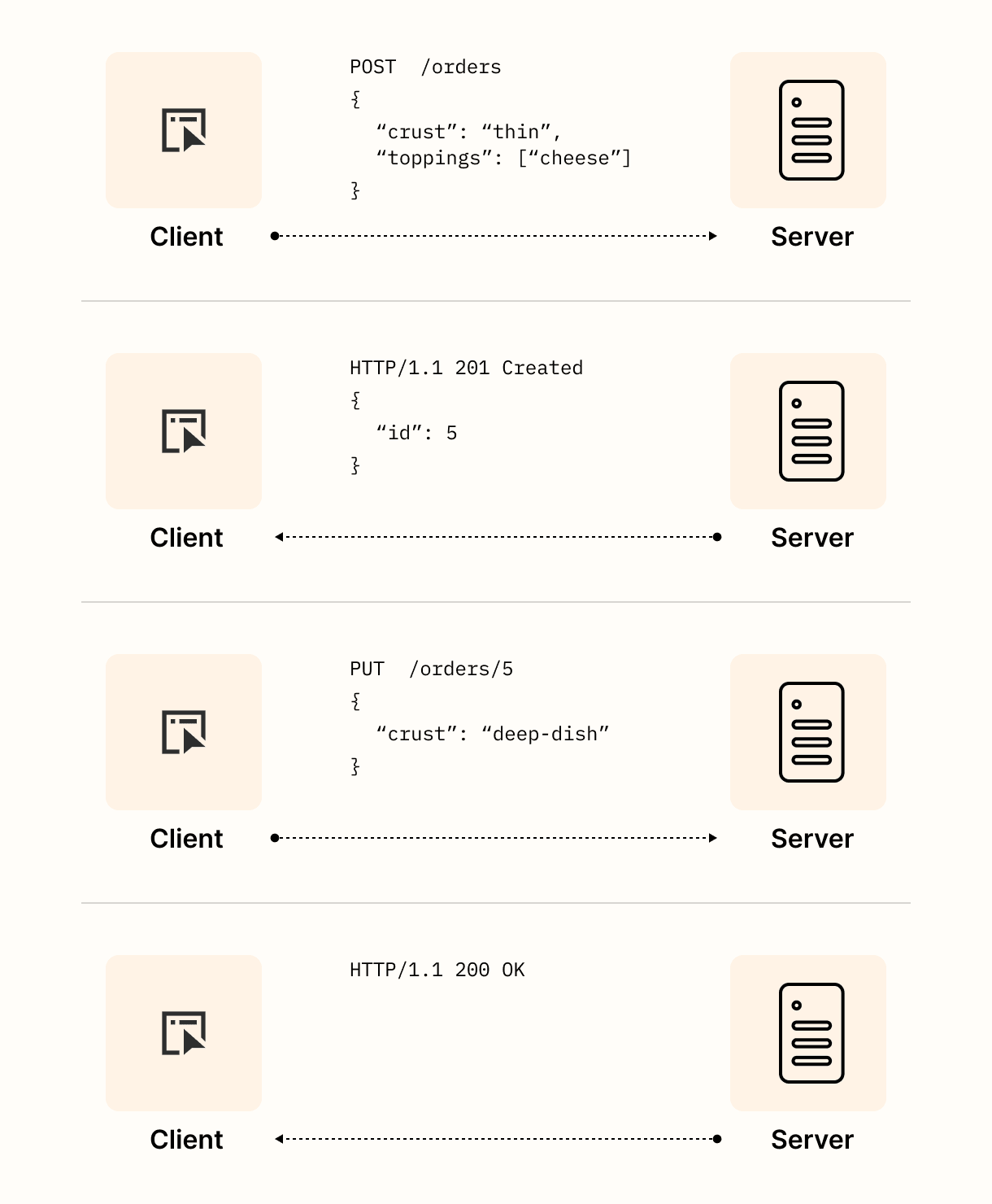
下一步是为资源分配URL。有很多可能性,但幸运的是,REST约定提供了一些指导。在典型的REST API中,一个资源将被分配两个URL模式。第一个是资源名的复数形式,如/orders。第二个是资源名的复数形式加上一个唯一标识符,用于指定单个资源,如/orders/<order_id>,其中<order_id>是订单的唯一标识符。这两个URL模式构成了我们的API将支持的第一个端点。这些被称为端点,只是因为它们位于URL的末尾,如http://example.com/<endpoint_goes_here>。
现在我们选择了资源并为其分配了URL,接下来我们需要决定客户端可以执行哪些操作。按照REST的约定,我们说复数端点(/orders)用于列出现有订单和创建新订单。带有唯一标识符的复数端点(/orders/<order_id>)用于检索、更新或取消特定订单。客户端通过在请求中传递适当的HTTP动词(GET、POST、PUT或DELETE)告诉服务器执行哪个操作。
GET
/orders
列出现有订单
POST
/orders
下订单
GET
/orders/1
获取订单 #1 的详细信息
GET
/orders/2
获取订单 #2 的详细信息
PUT
/orders/1
更新订单 #1
DELETE
/orders/1
取消订单 #1
在我们的订单端点的操作完善后,最后一步是决定客户端和服务器之间需要交换的数据。借鉴我们在第三章中的比萨店示例,我们可以说一个订单需要有面饼和配料。我们还需要选择一个客户端和服务器都可以使用的数据格式来传递这些信息。XML和JSON都是不错的选择,但为了可读性,我们将选择JSON。
在这一点上,你应该为自己鼓掌;我们设计了一个功能齐全的API!以下是使用这个API的客户端和服务器之间可能的交互方式:
链接资源
我们的比萨店API看起来很棒。订单像从未有过的那样源源不断地进来。生意如此好,事实上,我们决定要开始通过顾客追踪订单以衡量忠诚度。一个简单的方法是添加一个新的顾客资源。
就像订单一样,我们的顾客资源也需要一些端点。按照惯例,/customers 和 /customers/ 很合适。我们将跳过细节,但假设我们决定哪些操作对每个端点是有意义的,以及什么数据代表一个顾客。假设我们做到了这一切,我们面临一个有趣的问题:如何将订单与顾客关联起来?
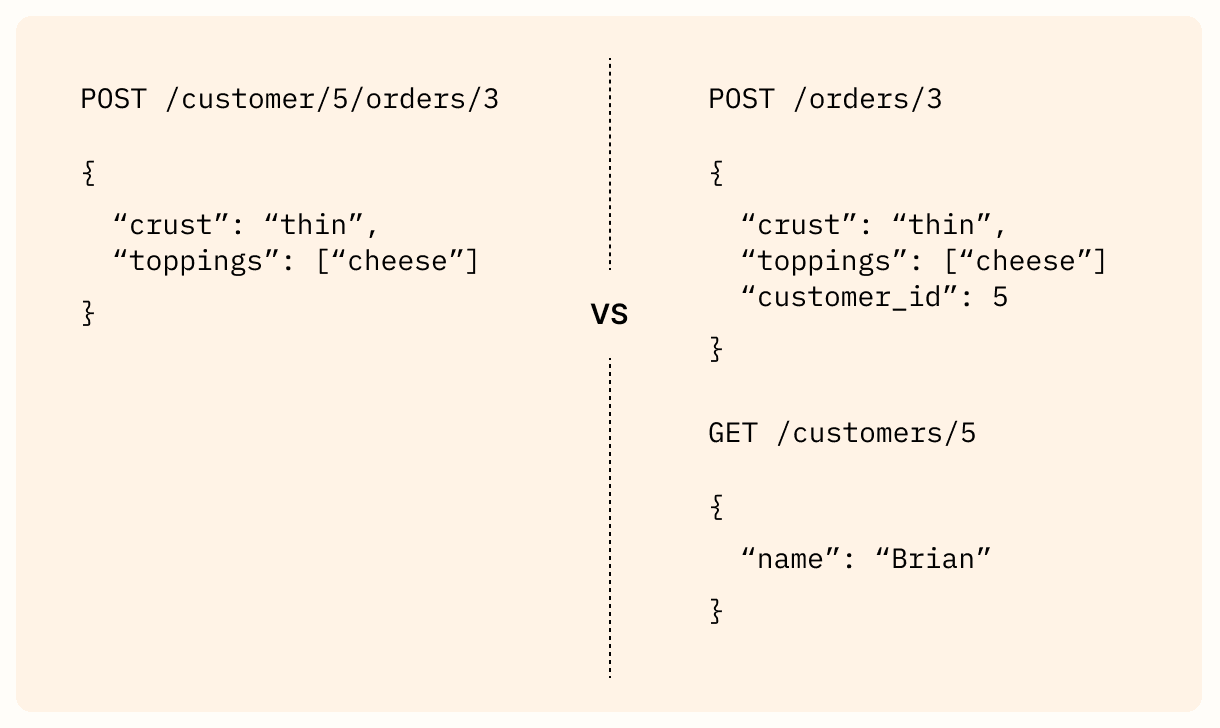
REST的实践者对于如何解决关联资源的问题存在分歧。有些人认为层次结构应该继续增长,提供像 /customers/5/orders 这样的端点来获取顾客5的所有订单,以及像 /customers/5/orders/3 这样的端点来获取顾客5的第三个订单。其他人则主张保持扁平,将关联的详细信息包含在资源的数据中。在这种范式下,创建订单需要发送一个带有 customer_id 字段的订单详细信息。这两种解决方案都被实际中的REST API使用,所以了解每种方案是值得的。
搜索数据
随着系统中的数据增长,列出所有记录的端点变得不切实际。想象一下,如果我们的比萨店有三百万份已完成的订单,并且你想找出有多少份订单的配料是意大利辣香肠。向 /orders 发送一个GET请求并接收全部三百万份订单将没有太大帮助。幸运的是,REST有一种聪明的方法来搜索数据。
URL还有另一个我们还没有提到的组件,即查询字符串。Query意味着搜索,String意味着文本。查询字符串是一个文本片段,放在URL的末尾,用于将信息传递给API。例如,在http://example.com/orders?key=value中,问号后面的所有内容都是查询字符串(query string)。
REST API使用查询字符串来定义搜索的详细信息。这些详细信息被称为查询参数(parameters)。API规定了它将接受哪些参数,这些参数的确切名称必须用于影响搜索。我们的比萨店API可以允许客户端通过使用这个URL来按配料搜索订单:http://example.com/orders?topping=pepperoni。客户端可以通过列出一个接着一个的方式包含多个查询参数,用和号("&")分隔它们。例如:http://example.com/orders?topping=pepperoni&crust=thin。
查询字符串的另一个用途是限制每个请求返回的数据量。通常,API将结果分为多个集合(例如100或500条记录),并一次返回一个集合。这个将数据拆分的过程称为分页(pagination)(类比将单词分页放入书籍中)。为了允许客户端浏览所有数据,API将支持查询参数,允许客户端指定它想要的数据页。在我们的比萨店API中,我们可以通过允许客户端指定两个参数:page和size来支持分页。如果客户端发出像 GET /orders?page=2&size=200 这样的请求,我们知道他们想要第二页的结果,每页200个结果,所以是201-400的订单。
第6章回顾
在本章中,我们学习了如何设计一个REST API。我们展示了API支持的基本功能以及如何组织数据以便计算机轻松消费。
我们学到的关键术语有:
SOAP:以标准化的消息格式为特点的API架构
REST:以操作资源为中心的API架构
资源(Resource):API中表示业务名词(如顾客或订单)的术语
端点(Endpoint):API的一部分,由URL组成。在REST中,每个资源都有自己的端点
查询字符串(Query String):URL的一部分,用于将数据传递给服务器
查询参数(Query Parameters):在查询字符串中找到的键值对(topping=cheese)
分页(Pagination):将结果拆分为可管理的块的过程
接下来
在下一章中,我们将探讨如何使客户端实时响应服务器上的变化。
最后更新于